- Google
dichiara che il suo scopo è di organizzare tutte le informazioni
disponibili e renderle universalmente accessibili e fruibili.
- Si tratta
di un compito benemerito ma anche ciclopico, visto il tasso di crescita
delle informazioni sul web. In realtà Google fa anche di più,
non necessariamente in funzione dell’obiettivo principale.
- Cominciamo
a riassumere come funziona un motore di ricerca.
- Il primo
compito consiste nel crawling, raccogliere
le informazioni dal web.
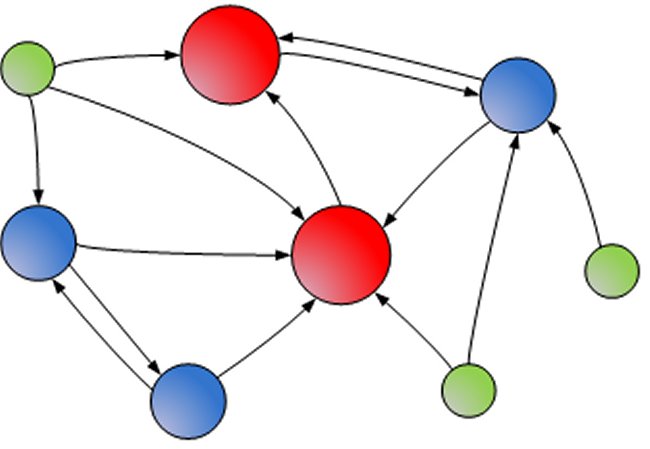
- Il principio
è semplice: si considera il web come un grafo formato da nodi, che
sono le pagine, e da archi, che sono i link e si assume che essi formino
un grafo fortemente connesso, ossia che a partire da un qualunque nodo
si possano raggiungere tutti gli altri. In realtà solo un quarto
ha questa caratteristica, ma un altro quarto è raggiungibile da
quello.
- Quindi
a partire da uno qualunque dei nodi del nucleo si può raggiungere
circa la metà di tutte le pagine web.
- I restanti,
o si rintracciano per altre fonti, ad esempio dal DNS o dai tweet, o altrimenti
restano sconosciuti e finiscono in quella parte denominata Hidden Web.
Un crawler parte da una lista di pagine (URL) radice, scarica ciascuna
di esse su dischi locali, ne analizza il contenuto, ne estrae i link, che
sono altre URL, e li aggiunge alla lista di pagine da scaricare.
- Dato che
una pagina contiene in media una trentina di link, l’esplorazione del grafo
fino al sesto livello di profondità già supera il miliardo
di nodi.
- Naturalmente
molti sono ripetuti e questo porta a un primo problema tecnico: come verificare
velocemente se una URL è stata già vista.
- Si potrebbero
usare soluzioni classiche come tabelle hash in memoria principale, sennonché
1 miliardo di URL occupano 80 GB (GigaByte, miliardi di byte).
- Quando
si sale ai 40 miliardi del web attualmente indicizzato, si arriva a 320
TB (TeraByte, migliaia di GB), che richiederebbero memorie troppo grandi
e costose.
- Occorre
quindi utilizzare tecniche di compressione e di ricerca su stringhe compresse,
oppure una combinazione furba di memorizzazione e scansione di dati su
disco.
- Ma questo
è solo uno dei tanti problemi di scalabilità di un crawler
web: per memorizzare 40 miliardi di pagine, con i loro metadati, che occupano
12 PB (PetaByte, milioni di GB) riducibili a 4 PB con la compressione,
è necessario usare database distribuiti come BigTable [6] o HBase
[7] e per poter visitare e rivisitare le pagine in tempi ragionevoli, il
crawler deve operare in parallelo su più macchine.
- Il processo
di crawling avviene in continuazione cercando di bilanciare la necessità
di freschezza dell’indice con quella di evitare di tempestare i server
con accessi troppo frequenti e di consumare troppa banda.
- Il secondo
compito è la costruzione di un indice
invertito, che per ogni parola riporta tutte le pagine in cui ricorre e
le posizioni di ciascuna occorrenza in ciascuna pagina.
- Anche
qui si usano tecniche di compressione che riducono l’indice a una dimensione
pari a circa il 10% del testo originale, ossia intorno a 1 PB.
- Per analizzare
e indicizzare i documenti, che avviene ripetutamente, man mano che i crawler
raccolgono nuove pagine, occorrono algoritmi paralleli basati su tecniche
come MapReduce [3] o una versione di questa specializzata per l’indicizzazione
come quella denominata Percolator [4].
- Anche
queste tecnologie [5] torneranno comode per altre analisi di dati su larga
scala descritte più avanti.
- Il terzo
compito è di rispondere alle query
degli utenti, scegliendo in una frazione di secondo i documenti rilevanti
e ordinandoli per rilevanza, in modo da presentarne una decina in prima
pagina.
- Anche
qui per garantire la scalabilità in termini di dimensioni dell’indice
e di numero di richieste da soddisfare, si distribuisce il lavoro su un
cluster di server: l’indice viene suddiviso in partizioni (shard), ciascuna
delle quali è replicata su cluster di qualche centinaio di macchine,
sia per ridondanza che per distribuzione del carico.
- Il web
server che riceve le query le smista a tutti i cluster e poi raccoglie
e ordina i risultati costruendo la pagina di risposta a cui aggiunge gli
snippet, porzioni di testo dei documenti selezionati dove ricorrono le
parole della query, che si fa dare da un document server che conserva una
cache locale di tutti i documenti scaricati dal web.
- In parallelo
alla ricerca dei risultati, la query viene anche inviata a un Ad server,
che seleziona le inserzioni pubblicitarie più mirate possibili agli
interessi dell’utente.
- Queste
vengono a loro volta incluse nella pagina restituita all’utente. I grandi
motori di ricerca rispondono attualmente a migliaia o decine di migliaia
di query al secondo.
- Le macchine
utilizzate per svolgere il servizio sono in genere server di basso costo
[13] dislocati in data center in varie parti del mondo composti di 50-100
mila server ciascuno, per un totale che supera il milione di server nel
caso degli operatori più grandi.
- Si stima
che il costo di tale infrastruttura, inclusi edifici e impianti, sia di
oltre $ 4 miliardi [1]. Il consumo di elettricità può essere
stimato in circa 300 MW, incluso circa il 12-15% impiegato per il raffreddamento
o dovuto a perdite [2]: l’equivalente di circa 230 mila utenze domestiche.
- Disporre
di tali massicce risorse di calcolo, consente però di utilizzarle
anche per svolgere analisi di grandi quantità di dati, come quelle
del prossimo compito ma anche di altre di cui parleremo più avanti.
- Il quarto
compito consiste nel calcolo di criteri di
ranking che sono utilizzati durante le ricerche, per selezionare i risultati
più rilevanti per una query e ordinarli.
- Oltre
al criterio di rilevanza basato sulla corrispondenza tra i termini della
query e il contenuto di un documento, si usa una misura di rilevanza assoluta
assegnata a ciascuna pagina.
- Per calcolarla
occorre analizzare le pagine e la struttura di interconnessione tra di
esse.
- Google
è celebre per aver inventato l’algomigliaia o decine di migliaia
di query al secondo.
- Le macchine
utilizzate per svolgere il servizio sono in genere server di basso costo
[13] dislocati in data center in varie parti del mondo composti di 50-100
mila server ciascuno, per un totale che supera il milione di server nel
caso degli operatori più grandi.
- Si stima
che il costo di tale infrastruttura, inclusi edifici e impianti, sia di
oltre $ 4 miliardi [1].
- Il consumo
di elettricità può essere stimato in circa 300 MW, incluso
circa il 12-15% impiegato per il raffreddamento o dovuto a perdite [2]:
l’equivalente di circa 230 mila utenze domestiche.
- Disporre
di tali massicce risorse di calcolo, consente però di utilizzarle
anche per svolgere analisi di grandi quantità di dati, come quelle
del prossimo compito ma anche di altre di cui parleremo più avanti.
- Il quarto
compito consiste nel calcolo di criteri di ranking che sono utilizzati
durante le ricerche, per selezionare i risultati più rilevanti per
una query e ordinarli.
- Oltre
al criterio di rilevanza basato sulla corrispondenza tra i termini della
query e il contenuto di un documento, si usa una misura di rilevanza assoluta
assegnata a ciascuna pagina.
- Per calcolarla
occorre analizzare le pagine e la struttura di interconnessione tra di
esse.
- Google
è celebre per aver inventato l’algoritmo di PageRank [11], che si
basa su fattori di connettività e rilevanza reciproca per stimare
l’importanza di una pagina.
- Siccome
il numero di link che puntano a una pagina influenza il suo PageRank, molti
si sono ingegnati per costruire delle link farm, ossia pagine fittizie
che si linkano l’una con l’altra per aumentare il proprio PageRank e quindi
la probabilità di apparire in cima alla lista dei risultati.
- Ovviamente
la presenza di tali farm va individuata onde combattere la manipolazione
del ranking.
- Cercare
di influenzare il ranking dei risultati dei motori di ricerca ha dato origine
a una nuova attività, detta SEO (Search Engine Optimization) [9],
svolta da aziende e professionisti che forniscono strumenti e consulenze
su come fare per aumentare il ranking delle pagine di un sito. I
- Infatti
ormai ai siti ci si arriva quasi esclusivamente attraverso i motori di
ricerca, quindi se un sito non rientra tra i primi dieci di una query,
rischia di restare incognito.
- Questo
fa riflettere sull’influenza che può avere un motore di ricerca
sui destini altrui, specie se non mantiene una completa neutralità
e possibilmente trasparenza nello svolgere i suoi compiti.
- Oggi PageRank
è solo uno delle varie centinaia di segnali usati nel calcolo della
rilevanza di una pagina e che vengono combinati in un unico valore attraverso
dei pesi calcolati con tecniche di apprendimento automatico.
- Con l’apprendimento
automatico entrano in gioco gli utenti.
- In sostanza
il motore di ricerca tenta di capire dal comportamento degli utenti quali
siano le risposte migliori. Quindi viene tracciato ogni link che viene
cliccato, quanto tempo passa tra la scelta di un link e di un altro, si
osservano le serie di query consecutive che un utente fa.
- Tali dati
vengono raccolti e forniti a un algoritmo di apprendimento, che estrapola
dagli esempi di risposte corrette le risposte corrette per casi futuri.
- Quanto
più numerosi sono gli esempi, tanto più accurate sono le
risposte, ma ne servono comunque almeno parecchi milioni.
- Il quinto
compito è la personalizzazione.
- Una volta
individuati i risultati potenzialmente più rilevanti in generale,
si riordinano sulla base di informazioni sull’utente.
- In particolare
possono essere usate informazioni di natura geografica (la posizione dell’utente),
comportamentali (storia delle precedenti ricerche, riformulazioni delle
query), sociali (utilizzo del grafo sociale a cui l’utente appartiene),
demografiche (categorie sociali di appartenenza), temporali (basate sui
pattern di attività dell’utente a seconda del periodo, ad esempio
giornaliero, settimanale).
- Il sesto
compito è la gestione della pubblicità.
Google usa una tecnica brevettata per selezionare gli annunci più
rilevanti, chiamata AdWords [8].
- AdWords
utilizza il principio delle aste per assegnare il posto in una pagina di
risposte per un annuncio all’inserzionista che offre la migliore combinazione
di prezzo e di CTR (Click Through Rate).
- Questo
significa che un annuncio che ha maggiori probabilità di essere
scelto costerà di meno.
- L’asta
avviene per aggiudicarsi le parole che appaiono nelle query. L’annuncio
viene pagato solo nel caso l’utente effettivamente clicchi sull’annuncio
(Pay per Click, PPC) e il prezzo d’asta è stabilito pari a 1 penny
in più dell’offerta immediatamente inferiore.
- Di recente
si è aggiunto un ulteriore compito,
che consiste nella raccolta e nell’analisi del cosiddetto Knowledge Graph
[14].
- Questo
grafo è composto di relazioni che legano tra di loro entità
nominate nel testo, quali persone, luoghi, prodotti, eventi.
- Effettuando
un’analisi linguistica dei testi è possibile riconoscere la presenza
e le relazioni ad esempio tra autori e libri, tra attori e film, le parentele
o le relazioni di lavoro tra persone e aziende, ecc.
- L’obiettivo
è sintetizzato nello slogan di consentire la ricerca di “Things,
not strings”.

Dati
e privacy
- Da quanto
detto, si capisce che un motore di ricerca raccoglie una mole di informazioni
sugli utenti e sulle loro attività sul web.
- Naturalmente
registra tutte le query effettuate ma anche conosce tutte le pagine che
un utente visita e quando: ce lo indica lui stesso quando riporta un risultato
su cui l’utente ha già cliccato in precedenza. Registra inoltre
il dominio, la lingua, il sistema operativo e il browser utilizzato.
- Con questi
dati è possibile determinare molti aspetti caratteristici di una
persona.
- Ad esempio
uno studio [12] dell’Università di Cambridge ha dimostrato che incrociando
dati del genere con gli apprezzamenti (Like) dati su Facebook da un gruppo
di persone è stato possibile individuare il colore della loro pelle
(con precisione del 95%), le loro inclinazioni politiche (85%), gli orientamenti
sessuali (80%), la loro religione (82%), le loro abitudini di fumo (73%),
di bere (70%) e di consumo di droghe (65%).
- Effettuando
l’analisi dei contenuti delle pagine visitate, è possibile ricostruire
un quadro degli interessi di una persona.
- Queste
tecniche sono alla base dei sistemi di raccomandazione, che hanno raggiunto
livelli notevoli di accuratezza, e costituiscono il fattore di successo
di servizi che offrono prodotti commerciali come Amazon e Netflix.
- La connessione
con i siti di e-commerce è palese ad esempio negli annunci che appaiono
sempre più spesso in alcune pagine e che riportano, a volte ossessivamente,
i prodotti che un utente ha visualizzato di recente.
- Naturalmente,
le aziende del web sostengono di svolgere queste analisi per fornire pubblicità
mirata e soddisfare meglio gli interessi sia degli inserzionisti che degli
utenti.
- Tuttavia
lo sfruttamento di tali dati potrebbe portare a vari tipi di abusi. Per
esempio una domanda di lavoro potrebbe venire scartata non in base all’esperienza
o alla qualifica del richiedente, ma sulla base dei risultati di analisi
statistiche di talento e carattere basato su dati raccolti sulla base delle
attività online del richiedente.
- Qualcosa
del genere già succede con LinkedIn, dove le persone da scegliere
per un lavoro sono individuate in base alla capacità delle persone
nel suo cerchio di conoscenze.
- Analogamente
le banche potrebbero usare dati raccolti in rete per decisioni sulla concessione
di crediti, le assicurazioni potrebbero valutare i rischi sulla base dello
stile di vita desunto dalle attività online delle persone.
- Tecniche
di opinion mining sono applicate per estrarre giudizi delle persone su
prodotti, ma si applicano altrettanto facilmente a riconoscere le opinioni
e gli orientamenti politici di chi scrive ad esempio nei blog o nei social
media.
Dati
e ricerca scientifica
- La quantità
di dati a disposizione ha fatto nascere una nuova disciplina chiamata Big
Data Science [16], che studia tecniche e algoritmi per analizzare ed estrarre
informazioni da grandi moli di dati.
- Diventa
possibile automatizzare il processo di osservazione che porta alle scoperte,
accelerando notevolmente la velocità del processo di indagine scientifica,
in modi che sono ancora difficili da capire.
- Mentre
finora ci si affidava allo sviluppo di modelli matematici basati su formule
ed equazioni per descrivere i fenomeni, i Big Data rappresentano i fenomeni
direttamente con grandi quantità di osservazioni e si utilizzano
tecniche automatiche di machine learning [15] per estrarre dei modelli
predittivi.
- Da una
parte queste possibilità aprono prospettive affascinanti per migliorare
la nostra capacità di analizzare o predire fenomeni, dall’altra
è inevitabile temere il rischio che questo possa compromettere o
erodere alcune libertà fondamentali dei cittadini.
- Uno degli
aspetti preoccupanti è che solo pochissime aziende private al mondo
siano dotate della capacità e delle risorse per acquisire tali dati
ed elaborarli a un livello impossibile per altri.
- Al di
là delle buone intenzioni, le aziende private non sono tenute a
indicare il tipo di elaborazioni che svolgono su tali dati e quali tipi
di informazioni ne ricavano.
- Spesso
rifiutano l’accesso a tali dati anche a chi intende fare soltanto degli
esperimenti scientifici.
- È
il caso dei colleghi di Milano Boldi e Vigna, che non hanno potuto accedere
direttamente al grafo sociale di Facebook per calcolare in “four degrees
of separation” [10] la distanza media tra gli utenti.
- Abbiamo
saputo che invece purtroppo questi dati sono stati forniti alla NSA, per
scopi che possiamo immaginare ma che restano oscuri. In sostanza alcune
grande aziende riescono ad ottenere grandi livelli di profitto applicando
analisi di dati per scopi pubblicitari.
- Vendendo
queste analisi pagano i costi dei servizi che offrono gratuitamente agli
utenti, che quindi li pagano consegnando loro in maniera automatica e inconscia,
attraverso le loro ricerche o i loro click, i loro dati personali e le
conoscenze che orientano le loro scelte.
Approfondimenti
- [1] J.
Hamilton. Counting servers is hard.
http://perspectives.mvdirona.com
/2013/07/17/CountingServersIsHard.aspx
- [2] Google
Inc. Efficiency: how we do it.
https://
www.google.com/about/datacenters/efficiency/internal/
- [3] MapReduce,
http://en.wikipedia.org/wiki/Mapreduce
- [4] D.
Peng, F. Dabek. Large-scale Incremental Processing Using Distributed Transactions
and Notifications. 9th USENIX Symposium on Operating Systems Design and
Implementation. 2010
- [5] M.
L. Braun. Big Data beyond MapReduce.
http://blog.mikiobraun.de/2013/02/big-databeyond-
map-reduce-googles-papers.html
- [6] BigTable,
http://it.wikipedia.org/wiki/BigTable
- [7] HBase,
http://en.wikipedia.org/wiki/HBase
- [8] AdWords,
http://en.wikipedia.org/wiki/Adwords
- [9] SEO,
http://it.wikipedia.org/wiki/Ottimizzazione_
(motori_di_ricerca)
- [10] P.
Boldi, S. Vigna. Four degrees of separation, really. In Proc. of the 2012
International Conference on Advances in Social Networks Analysis and Mining,
pages 1222-1227. IEEE Computer Society, 2012.
- [11] PageRank.
http://it.wikipedia.org/wiki/PageRank
- [12] F.
Lewsey. Digital records could expose intimate details and personality traits
of millions.
http://
www.cam.ac.uk/research/news/digital-records-couldexpose- intimate-details-and-personality-traits-of-millions.
- [13] Google
Platfom. http://en.wikipedia.org/wiki/
Google_platform
- [14] Knowledge
Graph. http://en.wikipedia.org/wiki/
Knowledge_Graph
- [15] Machine
Learning. http://en.wikipedia.org/wiki/
Machine_learning
- [16] Big
Data Science. http://en.wikipedia.org/wiki/
Big_data
|

